Introducing SpeechLoop
14 Aug 2021Here is a tool developed to evaluate multiple ASR (automatic speech recognition) engines and benchmark them to help answer the question, what is the best ASR for my dataset?
The Problem(s)
Every time an ASR is released, commercial or otherwise, it often comes with a claim that they are the best.
 It’s a very difficult claim to substantiate. How do they know they’re the best? Maybe they’ve publicly benchmarked? Sometimes they release a vague chart with cherry picked results.
Other times there’s a more detailed study. But still it’s hard to believe that the person doing the benchmarking is likely to report findings that show their ASR in a bad light.
It’s a very difficult claim to substantiate. How do they know they’re the best? Maybe they’ve publicly benchmarked? Sometimes they release a vague chart with cherry picked results.
Other times there’s a more detailed study. But still it’s hard to believe that the person doing the benchmarking is likely to report findings that show their ASR in a bad light.
Progress in the ML space moves very quickly. Overnight a new model is trained. What about the papers last year with the new dizzying end-2-end-2-end with mega-transformers? and with guest appearances from all your favourite childhood tv-shows. Were these compared? It can be difficult to keep track, plus you don’t want to keep hitting your competitors’ ASR all the time - this takes time away from R&D.
One can judge from experiment, or one can blindly accept authority.
Robert A. Heinlein
This is one of the reasons why SpeechLoop was developed.
Design Decisions
The following were some design decisions made while developing SpeechLoop:
- Easy to use with sensible defaults - following the “for humans” philosophy that other python packages have popularized.
- Heavy use of docker where required - Docker completely solves the issue of having to install big and heavily conflicting libraries, some of which are only needed for the install part of the process. If you have a reasonable amount of disk space and any x86_64 cpu you can go quite far with just sending bytes to an already built container.
- Limited number of 3rd party dependencies - this can be a challenge when installing a library, the more packages there are, the more that can go wrong.
- Pandas Dataframes - for easy analysis and simple WER calculation… the dataframe felt like the best fit where each row corresponds to an audio file and each ASR transcript would be a column.
Features
There are many features to list, but a video of simple usage will be even more useful.
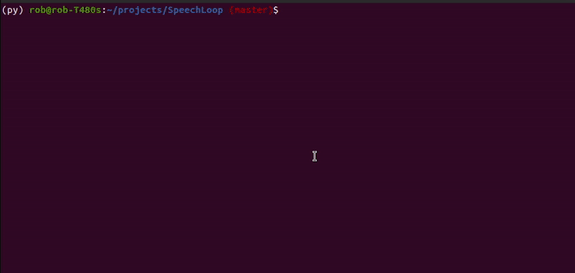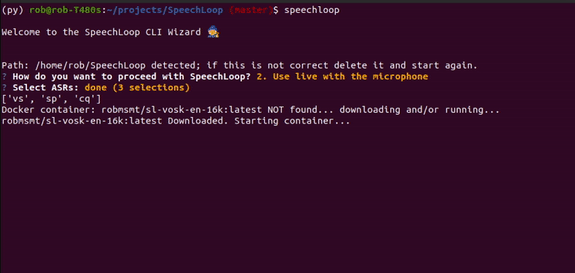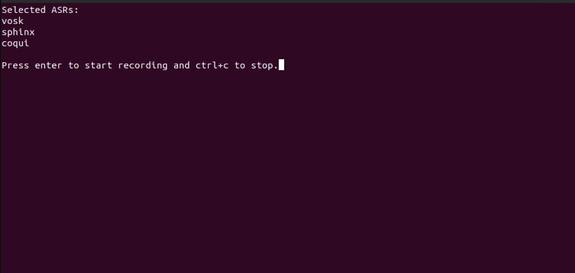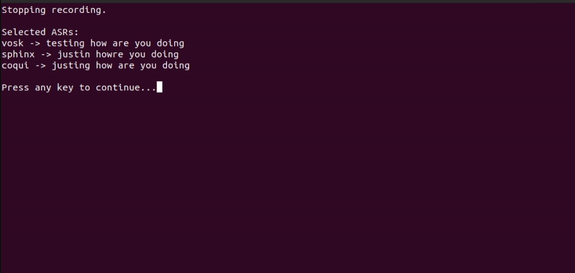 Here we demonstrate using the CLI to record microphone and pipe the data into the selected 3 ASRs.
Here we demonstrate using the CLI to record microphone and pipe the data into the selected 3 ASRs.
Above we run the CLI to evaluate against the included test dataset. It outputs a CSV. Below is a copy of the output text - following blogposts will focus on ASR results themselves.
------------------------------
Average value of vs_corrected_wer is 0.2308
------------------------------
Average value of sp_corrected_wer is 0.5128
------------------------------
Average value of cq_corrected_wer is 0.5513
Total inference time taken for vs is 0:01:15.081824
Total inference time taken for sp is 0:00:42.342496
Total inference time taken for cq is 0:01:27.646377
------------------------------
------------------------------
Finished, with total runtime: 0:03:42
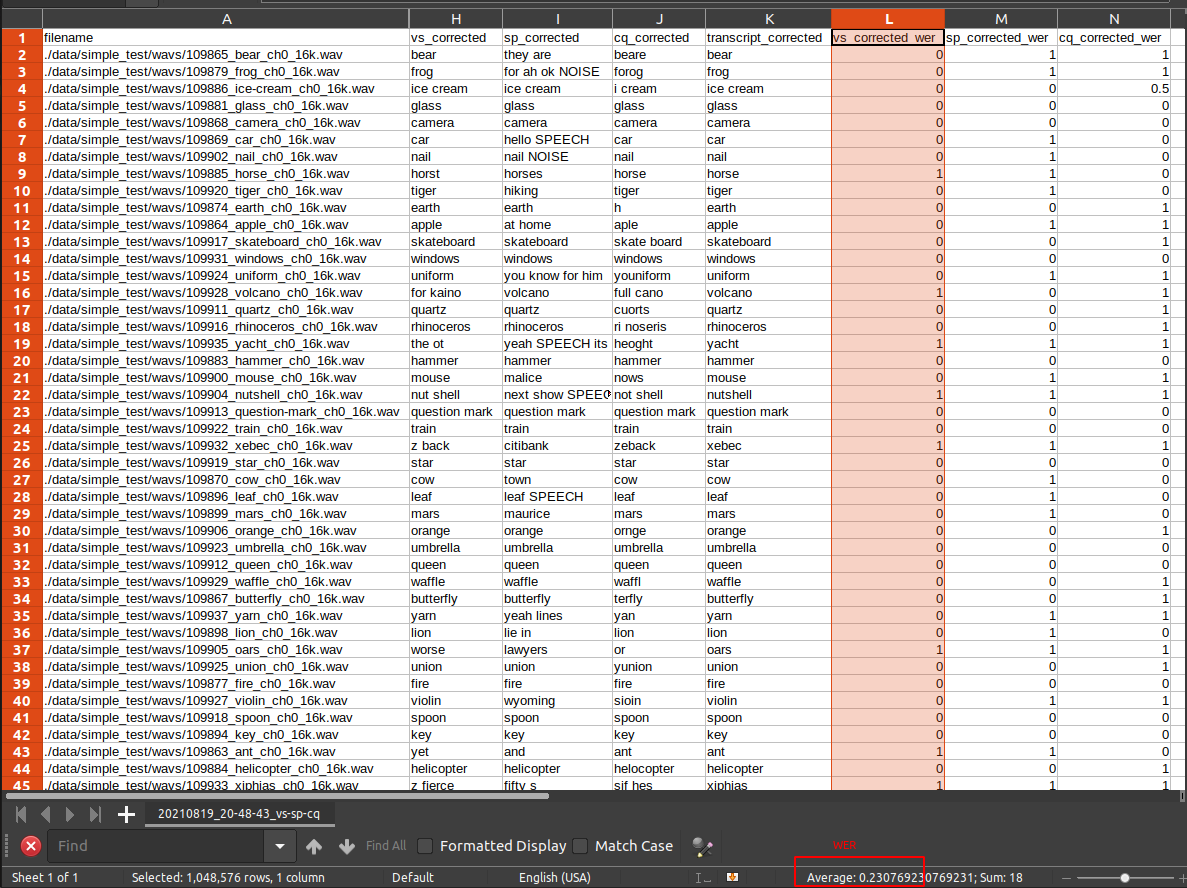 Often it’s good to load the CSV in excel-like tools to quickly skim the results. For anything more advanced a jupyter notebook might be the way to go.
Often it’s good to load the CSV in excel-like tools to quickly skim the results. For anything more advanced a jupyter notebook might be the way to go.
Future
- Different data formats (e.g. Kaldi has SCP, it would be nice to read those)
- Cost calculator for APIs
- More ASRs
- Automated benchmarks of common datasets - for example librispeech or one of the newly released huge datasets
Thanks
- Thanks to all ASRs - this tool just builds on top of others work. Without them it wouldn’t make sense.
- My employer MerlynMind who have actively encouraged this work - note that we are currently hiring for many roles.