Benchmarking ASRs - Results from the first 'Out of the Box' Test on an open source dataset
04 Sep 2021First ‘Out of the box’ results for 5 ASRs: VOSK vs Sphinx vs Coqui vs Google vs Amazon
1. Overview
In this post the testing procedure is discussed on the initial small dataset that is included with SpeechLoop. Speech systems are updated continuously so it’s sometimes hard to keep track of what the latest WER of each system is. This tool allows for easy benchmarking for a given dataset, to answer that question.
Although the test itself has a few limitations, it’s very small and the simplest which may be useful for those who want to quickly get up and running and evaluating different speech systems.
2. The Data
There are 78 WAVs of a single female person speaking very short nouns (mostly single words).
FileCount: 78
TotalLength: 00:01:15
ReadType: read
AudioQualityType: high
AudioNoiseType: none
MicQuality: high
AudioDist: near-field
Persons: solo
Language: EN
Accent: US
Gender: female
Filetype: wav
AudioFile: Signed 16 bit Little Endian, Rate 16000 Hz, Mono
Although this isn’t a great comprehensive test on it’s own - it is another single data point that can help paint the picture of how good the ASR is in real world settings. The details on the dataset can be found here.
Sometimes single word commands are harder for ASRs when using WER as the metric. This is for two reasons, firstly, because the utterances are usually very short there’s less information to evaluate (relies on the acoustic matching more so than pure unigram probabilities). Secondly, a single character when wrong can cause the word to be incorrect which contributes very large error to the overall score. This can make this a useful test to run!
3. Setup
Since this is the first benchmark, every step is repeated in detail so that others can follow.
Since we are planning to use GoogleASR and AWSTranscribe we need to setup the credentials. Suggested way is in the ~ /.bashrc:
#AWS
export AWS_ACCESS_KEY_ID=<accesskeyhere>
export AWS_SECRET_ACCESS_KEY=<secret_access_key_here>
#GOOGLE
export GOOGLE_APPLICATION_CREDENTIALS=/home/you/path/to/your/creds.json
Then re-source the bashrc with: source ~/.bashrc
Next, setup the repo as per the instructions:
git clone https://github.com/robmsmt/SpeechLoop && cd SpeechLoop
python3 -m venv venv/py3
source venv/py3/bin/activate
pip install -r requirements-dev.txt
Run:
cd speechloop
python main.py --input_csv='data/simple_test/simple_test.csv' --wanted_asr=all
4. ASRs
When we run the script we provide --wanted_asr=all this means (as of writing):
- sp = Sphinx - pocketsphinx 0.1.15
- vs = Vosk - based off of model en-small-us-0.15
- cq = Coqui - based off of model v0.9.3
- gg = GoogleASR - 21-09-06
- aw = AwsTranscribe - 21-09-06
The last two being cloud ASRs so all we can use to distinguish is today’s date.
5. Results
After some minor tidying up of the dataframe, see the Jupyter notebook for details… a dataframe is generated which we can export to JSON, as seen below.
Something interesting to note, all ASRs mistranscribed the WAVs “xebec” and “oars”.
There were many words that ALL ASRs got correct e.g. “class”, “camera”, “nail”, “skateboard”, “windows”, and “hammer”.
6. Conclusion
In summary, after transcription corrections for each ASR output, the following are the results.
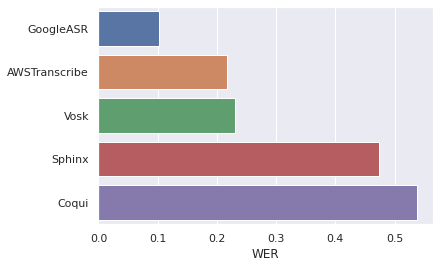
Overall the results are somewhat expected. CloudASRs tend to dominate, with VOSK being very good modern alternative. Coqui had
surprisingly bad results but it is expected to do better on longer sentences or with a customized language model.
For the next tests, we will attempt to tune each for the above dataset (where possible). As well as trying on everyone’s favourite opensource dataset…!